Лабораторная работа № 6
Разработка простейшего приложения
на основе технологии «клиент-сервер»
Цель работы:
Изучить основные принципы взаимодействия приложений, разработанных в
архитектуре «клиент-сервер», реализовать простейшее клиентское приложение, осуществляющее
доступ к базе данных по технологии ODBC (или другой технологии взаимодействия с базами данных), изучить основные принципы работы
клиентского приложения с API ODBC и с другими технологиями доступа к базам
данных.
Краткие теоретические сведения
Методы организации распределенных вычислений
Распространение динамически загружаемых библиотек и ресурсов пользовательского интерфейса программ привело к ситуации, когда прикладные программы стали представлять собой не единый программный модуль, а набор взаимосвязанных компонентов. Причем не все компоненты создавались теми же разработчиками, что и сама прикладная программа. Некоторые из них входили в состав ОС, другие поставлялись сторонними разработчиками, которые очень часто могли быть никак не связаны с разработчиками прикладной программы.
При этом любую прикладную программу (приложение) можно условно разделить на четыре основных уровня обработки данных:
- пользовательский интерфейс, отвечающий за отображение данных, представление их пользователю и взаимодействие с ним;
- бизнес-логики, реализующий специализированную логику обработки и преобразования данных, характерную для данной прикладной программы;
- БД, отвечающий за типовые операции получения, хранения, защиты и архивации данных, разделение доступа к ним;
- файловых операций, обеспечивающий работу прикладной программы с файловой системой ОС.
Каждый из этих уровней представляет собой логически цельную составляющую единой прикладной программы. При распределенной обработке данных каждая составляющая может выполняться отдельно (при условии сохранения взаимосвязи между всеми составляющими). В принципе, каждый из этих уровней можно далее разбить на подуровни и получить больше составляющих, общее число которых ничем принципиально не ограничено. Но с другой стороны, все составляющие любой прикладной программы можно разделить всего на две крупные части.
Первая из них обеспечивает нижний уровень работы приложения, отвечает за методы хранения, резервирования, доступа и разделения данных. Вторая организует верхний уровень работы приложения, включает логику обработки данных и интерфейс пользователя. Первая часть обеспечивает два нижних уровня обработки данных. Она, как правило, представляет собой набор компонент, входящих в состав ОС, либо созданных крупными сторонними фирмами-разработчиками, никак не связанными с созданием прикладной программы. Вторая часть обеспечивает реализацию двух верхних уровней обработки данных. Она включает в себя алгоритмы, логику и интерфейс пользователя, созданные разработчиками прикладной программы.
Таким образом, сложилось понятие приложения, построенного на основе архитектуры клиент-сервер. Первая часть в этой архитектуре стала носить название сервер данных, а вторая — клиент или клиентское приложение. При этом первая (серверная) часть приложения обеспечивает обработку данных на уровне файлов и БД. Для работы ее компонентов зачастую требуется наличие высокопроизводительной вычислительной системы. Вторая (клиентская) часть приложения, получая данные от сервера данных, обеспечивает их обработку и отображение в интерфейсе пользователя. По командам клиентской части сервер данных выполняет их добавление, обновление и удаление. Требования к вычислительным ресурсам, необходимым для выполнения компонент второй части, обычно существенно ниже, чем для первой.
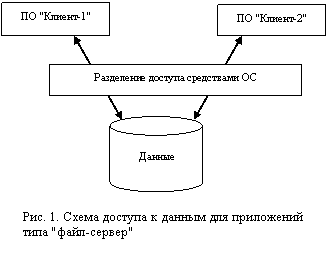 На начальном этапе развития архитектуры
клиент-сервер доступ к данным сервера осуществлялся на уровне файлов, а
разделение доступа к файлам обеспечивалось средствами ОС. Сервер данных
выполнял только примитивные процедуры хранения, копирования и защиты файлов от
несанкционированного доступа. Такие приложения иногда называют приложениями,
построенными по принципу "файл-сервер". В общем виде схема их работы
представлена на рис. 1.
На начальном этапе развития архитектуры
клиент-сервер доступ к данным сервера осуществлялся на уровне файлов, а
разделение доступа к файлам обеспечивалось средствами ОС. Сервер данных
выполнял только примитивные процедуры хранения, копирования и защиты файлов от
несанкционированного доступа. Такие приложения иногда называют приложениями,
построенными по принципу "файл-сервер". В общем виде схема их работы
представлена на рис. 1.
Видно, что в этом случае серверная часть выполняет только один, самый нижний уровень обработки данных, остальные уровни реализуются на клиентской части. Поэтому приложения типа "файл-сервер" можно только весьма условно отнести к приложениям, построенным в архитектуре "клиент-сервер". Хотя в них присутствует серверная компонента, ее функции, в основном, выполняются в ОС.
Главными недостатками приложений, построенных по принципу "файл-сервер", являются:
- высокая нагрузка на клиентскую часть, и как следствие, высокие требования к вычислительным ресурсам клиентской части;
- невозможность эффективно разделить доступ к данным при их одновременном использовании несколькими пользователями;
- невозможность организовать защиту данных иначе, как на уровне доступа ОС;
- высокая нагрузка на сеть для передачи файлов, если сервер данных и клиентское приложение работают на разных компьютерах в составе сети.
 Как
правило, разработчики, создающие ПО в архитектуре клиент-сервер, разрабатывают
именно клиентскую часть. Но тогда с одним сервером данных работают несколько
различных клиентских приложений (иначе нет никакого смысла создавать ПО в
данной архитектуре).
Как
правило, разработчики, создающие ПО в архитектуре клиент-сервер, разрабатывают
именно клиентскую часть. Но тогда с одним сервером данных работают несколько
различных клиентских приложений (иначе нет никакого смысла создавать ПО в
данной архитектуре).
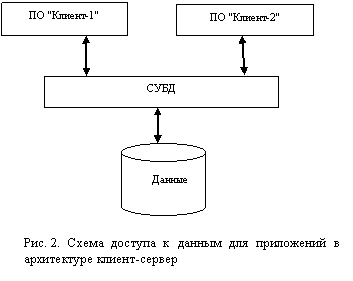
Проще всего полноценное приложение в архитектуре клиент-сервер возможно получить, если использовать БД для хранения данных и СУБД для доступа к данным. Схема работы такого приложения представлена на рис. 2.
Здесь серверная компонента реализует два уровня обработки данных – файловые операции и работу с БД. Все функции по хранению данных, доступу к ним, защите и резервному копированию данных в такой схеме реализует СУБД на сервере. Такой подход освобождает клиентские рабочие места от реализации этих функций и снижает требования к ним. Клиентское приложение не работает непосредственно с файлами и данными, оно обращается к СУБД с запросами на получение (просмотр) данных, их добавление, модификацию и удаление. При работе сервера данных и клиентского приложения на разных компьютерах в составе сети через сеть будут передаваться не все данные из БД, а только запросы клиента и ответы СУБД на них. Таким образом, в архитектуре клиент-сервер снижается нагрузка на сеть при обмене данными.
Общение с сервером СУБД происходит на языке структурированных запросов SQL (Structured Query Language). Базовый набор языка стандартизован ANSI. Самая распространенная редакция ANSI SQL92. SQL предназначен для построения запросов и манипуляции данными и структурами данных. У него нет ни переменных, ни меток, ни циклов, ни всего прочего, с чем привык работать нормальный программист. Надо четко представлять себе, что SQL оговаривает способ передачи данных в клиентскую программу, но никак не оговаривает то, как эти данные должны в клиентской программе обрабатываться и представляться пользователю.
Естественно, что базовый стандарт не может предусмотреть все потребности пользователей, поэтому многие фирмы производители СУБД предлагают свои собственные и часто непереносимые расширения SQL. Например, Oracle и IBM имеют собственные расширения оператора SELECT, которое позволяет эффективно разворачивать в горизонтальное дерево иерархически упорядоченные данные. Количество расширений может исчисляться десятками для сервера СУБД от одной фирмы.
Технология ODBC
Одним из наиболее распространенных средств, позволяющих унифицировать организацию взаимодействия с различными СУБД, является интерфейс ODBC. ODBC - Open Database Connectivity это интерфейс доступа к базам данных в среде Windows. Доступ к БД осуществляется при помощи специального ODBC драйвера, который транслирует запросы к БД на язык, поддерживаемый конкретной СУБД.
Для установления соединения с БД технология ODBC использует ODBC драйверы и источники данных, которые позволяют настроиться на сеанс конкретного пользователя СУБД. Для этого источник содержит имя пользователя и его пароль, а также, при необходимости, другую информацию, требуемую для присоединения к СУБД. ODBC драйвер представляет собой динамически загружаемую библиотеку, которая может использоваться приложением для получения доступа к конкретному серверу данных. Каждому типу СУБД соответствует свой ODBC драйвер.
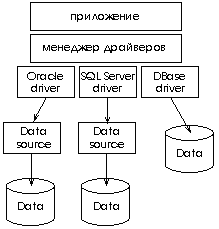 Взаимодействие
клиентской части ПО с СУБД осуществляется при помощи набора системных вызовов,
которые выполняются по отношению к источнику данных. Источник данных
взаимодействует с драйвером ODBC,
транслирует ему запросы клиента и получает ответы, а тот в свою очередь
обращается к СУБД. При необходимости работать с типом СУБД достаточно указать
другой тип ODBC
драйвера в источнике данных, при этом не требуется изменять клиентскую часть
ПО.
Взаимодействие
клиентской части ПО с СУБД осуществляется при помощи набора системных вызовов,
которые выполняются по отношению к источнику данных. Источник данных
взаимодействует с драйвером ODBC,
транслирует ему запросы клиента и получает ответы, а тот в свою очередь
обращается к СУБД. При необходимости работать с типом СУБД достаточно указать
другой тип ODBC
драйвера в источнике данных, при этом не требуется изменять клиентскую часть
ПО.
Такая двухступенчатая схема взаимодействия клиента с сервером данных обеспечивает независимость клиентской части от типа СУБД на сервере данных, но в целом снижает эффективность работы приложения, поскольку запрос, посланный клиентом, дважды передается различным библиотекам функций прежде, чем попадет на сервер. Решение вопроса о выборе способа взаимодействия с сервером данных остается за разработчиком клиентской части ПО и зависит от предъявляемых к нему требований.
ODBC реализует интерфейс доступа к разным SQL совместимым базам данных.
Рис.
3. Взаимодействие ODBC с различными
источниками данных
Клиент
|
ODBC
|
Диспечер драйверов ODCB
|
драйвер БД
|
БД
Идея заключается в том, что приложение может получать доступ к совершенно разным базам данных, не меняя при этом код.
Архитектура, по которой строится ODBC, легко наращиваемая. Для добавления нового типа БД нужно лишь написать драйвер и зарегистрировать его.
Основные преимущества ODBC:
· API функции одинаковые и не зависят от поставщика. (API - Application Programming Interface, интерфейс прикладной программы, посредством которого приложение получает доступ к операционной системе и другим сервисам. Использование API позволяет одинаковым образом осуществлять обработку файлов, вывод на принтер, передачу сообщений и выполнение других операций).
· SQL операторы могут быть сгенерированы на любой стадии при компиляции или выполнении.
· Данные принимаются в программу в едином формате.
Физически ODBC представляет собой набор динамических библиотек (DLL – Dynamic Link Library), которые обслуживают подключение и работу с конкретным типом базы данных. При запросе на подключение к определенной, заранее описанной базе "активизируется" определенная DLL - драйвер этого типа БД. Обращение к определенной базе данных происходит по имени так называемого источника данных ODBC или DSN.
DSN - Data Source Name - именованный источник данных ODBC. Источник данных содержит данные и сведения о подключении, необходимые для доступа к данным. Примерами источников данных могут служить базы данных Microsoft Access, Microsoft SQL Server, электронная таблица и текстовый файл. К примерам сведений о подключении относятся: папка на сервере, имя базы данных, сетевое имя, пароль, а также различные параметры драйвера ODBC, описывающие способ подключения к источнику данных.
Диспетчер использует информацию, связанную с именем для доступа к БД. С именем связана следующая информация:
- Местонахождение;
- Тип драйвера;
- Другие обязательные параметры.
Можно представить DSN как своего рода объявление БД на данном компьютере.
Существует три типа имен DSN:
- Пользовательский;
- Системный;
- Файловый.
В первом случае информация хранится в реестре Windows и привязана к конкретному пользователю (т.е. находится в области видимости только одного пользователя HKEY_CURRENT_USER\Software\ODBC\ODBC.INI). Во втором случае к конкретному компьютеру и каждый пользователь имеет доступ к данному источнику (HKEY_LOCAL_MACHINE\Software\ODBC\ODBC.INI). В последнем случае информация хранится в файле, что облегчает перенос проекта с компьютера на компьютер. Это просто текстовый файл с расширением *.dsn, обычно в папке C:\Program Files\Common Files\ODBC\Data Sources.
Первые два типа источников данных особенно полезны, когда требуется обеспечить дополнительную защиту, поскольку, таким образом, гарантируется, что источник данных может просматриваться только зарегистрированными пользователями и не может быть скопирован удаленным пользователем на другой компьютер.
Управление источниками данных ODBC (да и вообще настройкой всей системы ODBC) осуществляется с помощью специальной программы - ODBC-администратора. В Windows 9х - это исполняемый файл odbcad32.exe, который лежит в каталоге Windows\System. Запускать его можно напрямую, либо через Панель управления (значок "Источники данных ODBC (32-бит)"). В Windows 2000, XP - исполняемый файл odbcad32.exe лежит в каталоге WinNT\System32, а запускать его можно через Панель управления -> Администрирование -> Источники данных ODBC.
Технологии OLE DB и ADO
Технологии OLE DB и ADO были созданы компанией Microsoft и получили распространение в среде ОС типа Windows. Основой для их создания, в свою очередь, послужила технология OLE (Object Linking and Embedding — связывание и внедрение объектов), которая первоначально создавалась и развивалась в ОС типа Windows для обеспечения взаимосвязи между прикладными программами (в первую очередь — для связи между собой приложений Microsoft Office). После того, как в основу OLE была положена принципиально новая технология COM (Component Object Model — Модель многокомпонентных объектов), стало возможным использовать OLE для связи любых типов программ.
В результате применения технологии OLE к решению задачи организации взаимодействия клиентской и серверной частей приложения была получена новая технология — OLE DB (OLE for DataBases — OLE для баз данных).
С точки зрения Microsoft, OLE DB представляет собой следующую ступень развития технологии ODBC. Обе технологии образуют относительно независимый программный слой, использующий однотипные интерфейсы прикладных программ (API) для доступа к разным типам СУБД. Их работа обеспечивается программными модулями, которые учитывают специфические особенности каждой СУБД. В OLE DB полностью реализован принцип универсального доступа к разнотипным СУБД. Наибольшие различия технологий ODBC и OLE DB проявляются в использовании некоторых основных терминов и в окружающем контексте.
Технология ADO родилась в результате объединения OLE DB с еще одной технологией, созданной Microsoft — ActiveX. Отсюда происходит и название технологии ADO — ActiveX Data Object (объекты данных ActiveX).
С точки зрения разработчика клиентской части приложения в архитектуре «клиент-сервер» ADO представляет собой прикладной объектный интерфейс более высокого уровня, чем OLE DB. Этот интерфейс упрощает доступ к средствам OLE DB разработчикам, использующим языки высокого уровня. В настоящее время разработчик этих технологий — компания Microsoft — выпустила уже несколько версий библиотек ADO и продолжает развивать эту технологию.
Однако развитие этих технологий ограничено, прежде всего, тем, что они ориентированы в основном только на вычислительные системы, построенные на базе ОС типа Windows. И хотя появляются версии ADO для других типов ОС, переносимость приложений, созданных на основе этой технологии, на вычислительные системы, не использующие Windows, остается проблемой.
Способы организации взаимодействия клиентской и серверной частей приложений на основе архитектуры «клиент-сервер» не ограничиваются только перечисленными технологиями. Сложно даже перечислить их все в рамках данной книги, а тем более подробно описать. Более подробно об организации приложений на основе архитектуры «клиент-сервер» можно узнать в [25, 27, 48, 77, 79].
Поддержка технологий доступа к СУБД в системах программирования
Появление и развитие различных технологий доступа клиентской части приложений к серверу данных не осталось без внимания разработчиков систем программирования (особенно если учесть, что такие создатели новых технологий, как компания Microsoft, являются одновременно и разработчиками систем программирования). Поэтому на рынке систем программирования появились системы, поддерживающие основные существующие технологии доступа клиента к серверу данных.
Если разработчик клиентской части приложения останавливает свой выбор на одной из существующих стандартных технологий, то в этом случае он не только избегает зависимости создаваемого приложения от типа СУБД, но и получает возможность выбора среди систем программирования, доступных на рынке. Это обусловлено тем, что практически все современные системы программирования поддерживают такие распространенные технологии как ODBC или ADO и предоставляют разработчикам инструменты и библиотеки, снижающие трудоемкость создания клиентов на основе таких технологий. В дальнейшем возможности созданного приложения будут ограничены только возможностями выбранной технологии: например, технология ADO имеет широкие возможности, но ее применение ограничено только вычислительными системами, построенными на базе ОС типа Windows.
Таким образом, выбирая стандартную технологию, разработчик получает выигрыш в выборе СУБД и средств разработки, но проигрывает в производительности, так как универсальные методы доступа к СУБД менее эффективны, чем специализированные.
Если же разработчик клиентской части приложения выберет для взаимосвязи с сервером данных специализированную технологию, ориентированную на определенный тип СУБД, то он, безусловно, получит более высокую скорость обмена данными между сервером и клиентом. Однако в этом случае он будет ограничен и в выборе типа СУБД, и в выборе средств разработки. Первое утверждение очевидно, так как специализированный метод доступа ориентирован на определенный тип СУБД (а зачастую — и на определенную версию СУБД). Второе утверждение основано на том, что специализированные методы доступа к СУБД либо совсем не поддерживаются системами программирования от других производителей, либо имеют ограниченные инструменты поддержки, снижающие эффективность разработки. В этом случае лучше всего использовать систему программирования, созданную тем же производителем, что и СУБД (в настоящее время ведущие производители СУБД предлагают и свои средств разработки).
Выигрыш в эффективности доступа клиента к серверу данных при использовании специализированных методов обусловлен еще одним немаловажным фактором: все производители СУБД заинтересованы в создании как можно большего количества клиентских приложений, ориентированных именно на их СУБД. Поэтому все полезные для клиентов нововведения появляются в первую очередь именно в специализированных средствах доступа и только потом уже, если это возможно, переносятся в средства обеспечивающие поддержку стандартных технологий.
Каждый из описанных путей создания клиентского приложения в архитектуре «клиент-сервер» не лишен своих преимуществ и недостатков. Выбор одного из них остается за разработчиком и зависит от тех условий, для которых создается то или иное приложение.
Проблемы и недостатки архитектуры «клиент-сервер»
Приложения, созданные на основе архитектуры «клиент-сервер», получили ряд преимуществ по сравнению с приложениями, не использующими распределенных вычислений, а также приложениями, созданными на основе архитектуры «файл-сервер». Тот факт, что основные производители систем программирования включили в свои системы средства поддержки разработки приложений в этой архитектуре, обусловил широкое распространение таких приложений на рынке программных средств.
В то же время, сама по себе архитектура «клиент-сервер» не лишена некоторых недостатков:
· функции управления данными возложены на сервер данных, но обработка данных (прикладная логика или бизнес-логика) по-прежнему выполняется клиентами, что не позволяет существенно снизить требования к ним, если логика приложения предусматривает достаточно сложные манипуляции с данными;
· при необходимости изменить или дополнить логику обработки данных необходимо выполнить обновление клиентских приложений на всех рабочих местах, что может быть достаточно трудоемко;
· если необходимо изменить только внешний вид интерфейса пользователя (отображение данных), но оставить неизменной логику обработки данных, при этом чаще всего требуется заново создать и установить на рабочем месте новый вариант клиентской части системы;
· при использовании мощной промышленной СУБД требуется наличие лицензии на подключение к СУБД для каждого рабочего места, где установлена клиентская часть программного обеспечения.
Наличие хранимых процедур и других мощных средств, расширяющих возможности серверов данных, позволяет перенести на них так же и значительную долю функций прикладной логики. Это несколько нивелирует большинство указанных недостатков архитектуры «клиент-сервер», но не позволяет полностью избавится от них по следующим причинам:
· внутренние языки СУБД, используемые для создания хранимых процедур и других подобных средств, хотя и сравнимы в настоящее время по своим возможностям с языками современных систем программирования, но всё же уступают им — поэтому не все функции прикладной логики могут быть реализованы на сервере данных столь же эффективно, как на клиенте;
· хранимые процедуры, триггеры и другие средства СУБД, созданные на ее внутреннем языке, после предварительной компиляции сохраняются во внутреннем коде СУБД (но не в машинных кодах), а во время исполнения интерпретируются СУБД — поэтому они проигрывают в производительности результирующим программам, созданным в машинных кодах.
При разработке приложений в архитектуре «клиент-сервер» вовсе не следует стремиться все функции прикладной логики возложить на сервер данных. Следует помнить, что СУБД интерпретирует код, а потому серверу всегда потребуется больше ресурсов для выполнения тех же функций, которые на клиенте выполняются в машинных кодах. Разумное распределение функций между клиентской и серверной частью приложения зависит от многих факторов, в том числе от количества клиентов, мощности клиентских и серверного компьютеров и др.
Еще одним средством, которое может расширить возможности приложений, построенных на основе архитектуры «клиент-сервер», является использование терминального доступа в сочетании с возможностями этой архитектуры. В этом случае компьютер-клиент, на котором выполняется клиентская часть приложения, одновременно становится терминальным сервером, к которому могут подключаться компьютеры-терминалы. Тогда вся логика организации пользовательского интерфейса выполняется компьютерами-терминалами, прикладная логика приложения выполняется на терминальном сервере (который одновременно является клиентом), а логика обработки данных и файловые операции выполняются на сервере данных. Поскольку клиентов может быть несколько, то и терминальных серверов в такой структуре может быть несколько. Тогда пользователь компьютера-терминала либо подключается только к заданному терминальному серверу, либо имеет возможность выбрать один из доступных терминальных серверов для подключения.
Порядок выполнения работы
- Получить вариант задания у преподавателя.
- Разработать структуру БД в соответствии с полученным заданием, выбрать тип используемой СУБД (по согласованию с преподавателем).
- Создать БД в соответствии с разработанной структурой. При необходимости реализовать хранимые процедуры, триггеры и другие средства обработки данных на сервере.
- Изучить принципы построения приложений на основе архитектуры «клиент-сервер». Выбрать технологию для взаимодействия с серверной частью.
- Выбрать систему программирования для разработки клиентской части приложения (по согласованию с преподавателем).
- Используя выбранную технологию взаимодействия с серверной частью, с помощью выбранной системы программирования разработать клиентскую часть приложения.
- Написать и отладить программу на ЭВМ.
- Подготовить и защитить отчет.
- Продемонстрировать разработанное приложение преподавателю.
Требования к оформлению отчета
Отчет по лабораторной работе должен содержать следующие разделы:
· Краткое изложение цели работы.
· Задание по лабораторной работе.
· Схему организации БД (БД должна содержать не менее трех взаимосвязанных таблиц).
· Описание выбранной технологии взаимодействия клиентской и серверной частей приложения.
· Текст программы (оформляется при необходимости по согласованию с преподавателем).
· Выводы по проделанной работе.
Основные контрольные вопросы
1. Назовите уровни обработки данных.
2. Назовите основные особенности архитектуры "клиент-сервер"
3. Какие функции может выполнять сервер в архитектуре "клиент-сервер"?
4. Что такое файл-сервер? Назовите особенности его реализации.
5. Какие существуют методы работы с базами данных?
6. Дайте характеристику интерфейса ODBC.
7. Какие источники данных могут быть использованы ODBC?
8. Как осуществляется работа программы при использовании ODBC?
Варианты заданий
Общие требования к разрабатываемому приложению:
1. Приложение должно реализовывать простейшую прикладную функцию в соответствии с заданием. Конкретный состав выполняемых функций разрабатывается студентами самостоятельно, при необходимости согласовывается с преподавателем.
2. Функции приложения должны выполняться на основе взаимодействия с БД. Состав таблиц и структура БД разрабатывается студентами самостоятельно, согласовывается с преподавателем. Как правило, БД должна содержать 3-5 взаимосвязанных таблиц.
3. Приложение должно работать в двух режимах: административном режиме и режиме пользователя. В административном режиме должно быть доступно больше функций по управлению данными (состав функций для каждого режима указан в варианте задания). Два режима работы приложения должны быть реализованы либо в виде двух программных модулей, либо в виде двух режимов работы одного программного модуля – в этом случае выбор режима работы должен выполняться на основе ввода имени и пароля пользователя при запуске программного модуля.
4. Интерфейс клиентской части приложения должен быть простым, понятным и ориентированным на пользователя. В частности, при выборе данных для взаимосвязанных таблиц выбор должен осуществляться из связанной таблицы с наглядным отображением значащих полей, поиск должен осуществляться по заданным пользователем критериям, при возникновении ошибок, связанных с обработкой данных, должны выдаваться соответствующие сообщения (не сообщения сервера взаимодействия с СУБД!).
|
№ |
Функции приложения |
Функции администратора |
Функции пользователя |
|
1.
|
Библиотека |
Ввод и редактирование данных об имеющихся книгах. |
Библиотекарь: выдача книг и получение книг от читателей. |
|
2.
|
Библиотека |
Библиотекарь: обработка поступивших заявок, выдача книг и получение книг от читателей. |
Читатель: поиск информации о наличии книг, заявка на получение найденной книги. |
|
3.
|
Театральная касса |
Ввод и редактирование данных о спектаклях и наличии билетов. |
Кассир: продажа и возврат билетов. |
|
4.
|
Театральная касса |
Кассир: обработка поступивших заказов, продажа и возврат билетов. |
Зритель: поиск информации о спектаклях и о наличии билетов на них, заказ билета на выбранный спектакль. |
|
5.
|
Железнодорожная касса |
Ввод и редактирование данных о расписании и маршрутах движения поездов. |
Кассир: продажа и возврат билетов. |
|
6.
|
Железнодорожная касса |
Кассир: обработка поступивших заказов, продажа и возврат билетов. |
Пассажир: поиск информации о возможности проезда до станции назначения и о наличии мест, заказ билета на определенный поезд. |
|
7.
|
Автосалон |
Ввод и редактирование данных об автомобилях, их комплектации и сроках поставки. |
Продавец: заключение договоров о покупке автомобиля, заказ автомобиля нужной комплектации. |
|
8.
|
Автосалон |
Продавец: обработка заявки, заключение договоров о покупке автомобиля, заказ автомобиля нужной комплектации. |
Покупатель: поиск информации об автомобиле нужной комплектации, формирование заявки на автомобиль. |
|
9.
|
Мебельная фабрика |
Ввод и редактирование информации о конструкции мебели. |
Изготовитель: ввод информации о поступлении комплектующих на склад и об изготовлении мебели. |
|
10. |
Мебельная фабрика |
Изготовитель: ввод информации о поступлении комплектующих на склад и об изготовлении мебели, продажа изготовленной мебели. |
Покупатель: поиск наличия необходимой мебели, заказ и приобретение мебели по заказу. |
|
11. |
Стадион |
Формирование расписания матчей. |
Кассир: продажа билетов и возврат проданных билетов. |
|
12. |
Стадион |
Кассир: обработка заказов, продажа билетов и возврат проданных билетов. |
Зритель: поиск информации об интересующем матче, заказ билетов на выбранный матч. |
По согласованию с преподавателем, допускается объединять однотипные по функциям задания (например, варианты 1 и 2) для выполнения их группой студентов (2-3 человека). В этом случае разрабатывается одна БД и несколько приложений (в соответствии с вариантами задания).
Допускается выполнение студентами своих собственных вариантов работы (по выбору) при условии согласования с преподавателем функций разрабатываемого приложения.
Рекомендуемая литература
1. Молчанов А.Ю. Системное программное обеспечение: Учебник для вузов. 3-е изд. — СПб.: Питер, 2010 — 400 с.
2. Гордеев А.В. Операционные системы: учебник для вузов. — СПб.: Питер, 2004 — 416 с.
3. Карпова Т.С. Базы данных: модели, разработка, реализация. — СПб.: Питер, 2001 — 304 с.
4. Олифер В.Г., Олифер Н.А. Сетевые операционные системы: учебник для вузов. — СПб.: Питер, 2008 — 672 с.
5. Таненбаум Э. Современные операционные системы. 2-е изд. — СПб.: Питер, 2007 — 1038 с.
6. http://www.codegear.com
10. http://www.microsoft.com/rus/msdn/vs/default.mspx
11. http://msdn.microsoft.com/ru-ru/aa496123.aspx
12. http://www.citforum.ru/programming/32less/les44.shtml
13. http://www.citforum.ru/cfin/prcorpsys/index.shtml
14. http://www.visual.2000.ru/develop/ms-vb/cp9907-2/msado1-1.htm
15. http://www.interface.ru/fset.asp?Url=/borland/com_dcom.htm
16. http://www.citforum.ru/programming/middleware/midas_4.shtml